
I started an AI assistant project called Nomi. We heavily rely on voice interactions, but using OpenAI’s realtime services for this was too expensive. I wanted to find a solution. In this post, I will share the journey of how I accidentally made using OpenAI’s services more than 100 times cheaper while trying to replicate one of their features. I’ve been using this method for six months, even before they released the real-time API.
This post will not be overly technical; I aim to make it as accessible as possible. However, if you are interested in more technical details, feel free to reach out to me on social media or by email. If you’re looking for the code, you can find it here.
First steps Cost Reduction 🔗
Their real-time API is priced at $100 per million input tokens and $200 per million output tokens, making it one of the most expensive large language model (LLM) APIs available.
Voice processing is generally very expensive, so I needed to find a way to reduce the costs. In their real-time API, OpenAI suggests handling Voice Activity Detection (VAD) locally on your machine to gain control and efficiency. VAD is a technology that detects when someone is speaking, allowing the system to process only the relevant audio segments. This is the approach I took previously because I worked on a project where understanding conversations was crucial. I believe that avoiding streaming all audio chunks to the API is a great first step toward cost reduction.
Choosing Golang 🔗
I chose Golang for its strengths in managing concurrency and developing cross-platform applications. Voice processing requires concurrency and low-level operations, areas where Golang excels. Although cross-platform development had its challenges, I succeeded with persistence. You can view multiple Dockerfiles in this repository. I am currently working on targeting specific platforms like darwin/intel and windows/arm64.
While I love Python, especially for RL and ML, Golang’s simplicity and constraints are advantageous. It’s vital for cross-platform tasks and simplifies concurrency, even if languages like Python with asyncio or Rust with Tokio offer robust asynchronous features. Despite some performance limitations, such as low-latency challenges in bpfsnitch, Golang’s reliability makes it ideal for this project. Solomon Hykes, the creator of Docker, also wrote about why they used Golang for Docker, and it is really interesting to read.
For Nomi, some parts might still be in Python due to machine learning model constraints. Golang simplifies code maintenance, while deploying Python is more complex.
Choosing Whisper and OpenAI API 🔗
For voice processing, I wanted to have reproducible results on my laptop but also the ability to outsource the processing when needed. So I chose to use Whisper and the option to utilize OpenAI’s Whisper API. Whisper is an open-source speech recognition system developed by OpenAI, known for its high accuracy and ability to transcribe speech in multiple languages. By using Whisper, I could process voice inputs locally, but also have the option to use the OpenAI Whisper API when necessary.
The OpenAI Voice Transcribe API is really good and not too expensive, but it takes a lot of time to process the request. In fact, the inference time is longer than the actual speech, so I had to run it in parallel to avoid delaying the rest of the system:
go func() {
text, err := transcribeAsync(apiData)
if err == nil {
processText(text)
}
}()
Optimizing the Transcription 🔗
The initial results were good, but simply using the transcribe function was still too slow. I had to implement a few heuristics using the VAD, detect pauses in speech, flush data periodically, and I implemented a double buffer strategy to enhance efficiency. This approach processes overlapping segments, correcting first-buffer errors. Breaking chunks into shorter segments allows for faster inference, enabling text processing to keep up with ongoing speech:
primaryBuffer := createBufferManager()
secondaryBuffer := createBufferManager()
After that, I prioritized longer segments, assuming they are from a higher-quality source. At some point, I believe I will be able to determine speaker changes with multiple buffers, but that is not implemented yet.
High-Level Architecture 🔗
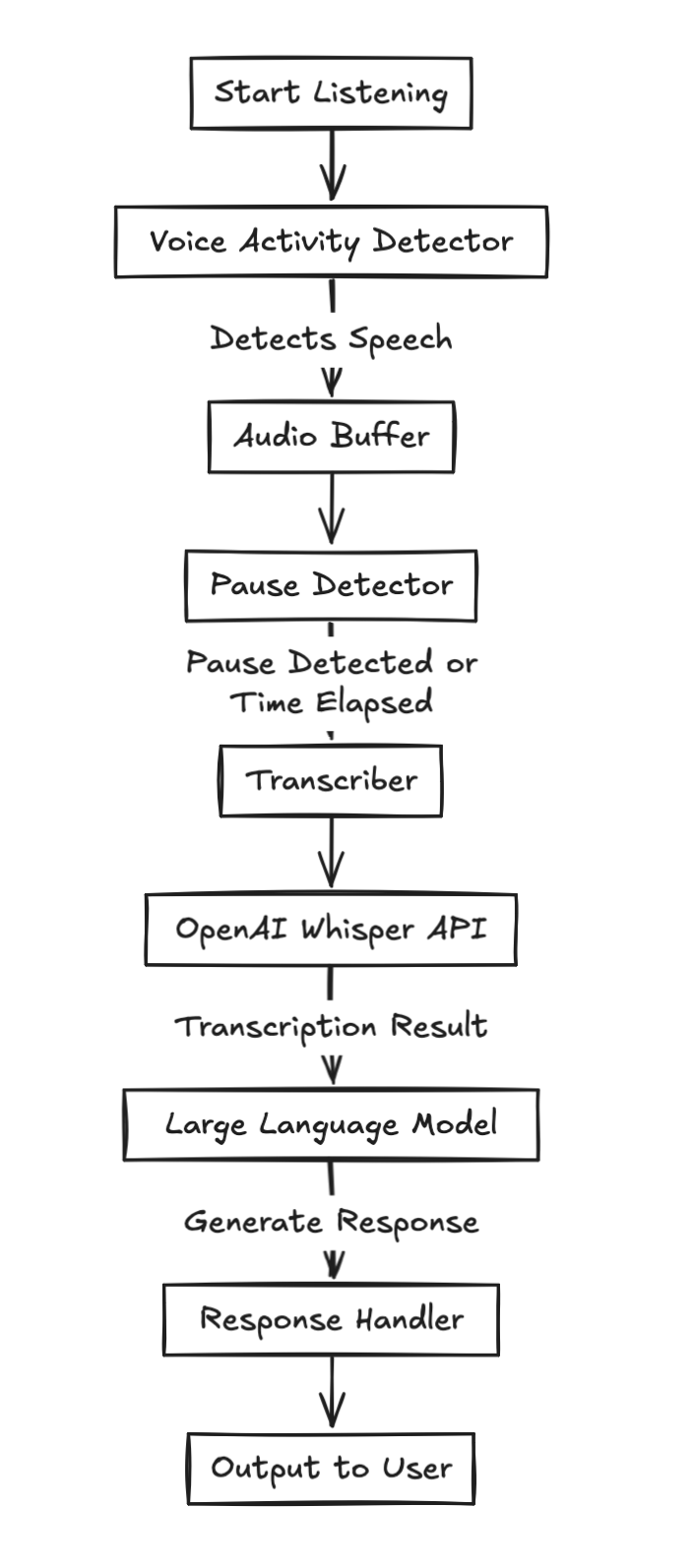
By combining a Voice Activity Detector (VAD), a speech transcriber, and a Large Language Model (LLM), I was able to achieve a round-trip of voice transcription, similar to the real-time API, while managing the cost of latency. The slowest component is the Whisper API; usually, there is a delay of 200–300 milliseconds for the full processing – but it feels instant with an on device Whisper. This makes it slightly slower than the real-time API but between 100 to 1000 times cheaper. I tried using text-to-speech, but that was even worse because the API is even slower.
The idea is to launch the program, which starts listening. Once there is sufficient energy in the audio chunks, it pushes the chunks into a buffer. After enough time or a pause is detected, it releases the data to a transcriber, which calls the OpenAI Whisper API. The result—either at the end of the speech or during pauses—is then used to call an LLM to get the response.
Some Notes on Voice Transcription 🔗
One thing I noticed about Whisper is that specifying the language is very important; transcription accuracy is significantly improved. Even my English becomes acceptable! I tried it with extreme accents, and it still worked. Whisper is really a great technology, thanks to the OpenAI team for making it open-source.
I also love Whisper because, on a Mac laptop, it remains very efficient, and I could transcribe long recordings from my job without any problem.
I still have unsolved issues, such as handling multiple speakers and detecting speaker changes, but I am working on it, and some models already have this feature.
Finally, I chose not to incorporate live transcription into Nomi because I wanted to keep it simple and focus on the core features, rather than committing to skills that are not yet mature—though I believe they will be in a matter of months. We realized that most people are willing to press a button, making the entire process synchronous, so I am focusing on that.
I believe this could be helpful for other developers out there, so feel free to reuse the VAD and transcription code and adapt it to your needs. I am confident that OpenAI will continue to make such achievements, and I am very happ